本帖最后由 金金金 于 2024-9-11 13:03 编辑
如何解决因式分解带来的推荐冷门,热门关键词的问题。 在回答这个问题的时候, 想到了近几年在做搜索推荐系统的过程中, 学术界和工业界的一些区别。 正好最近正在做技术规划, 于是写偏文章说下工业界完整推荐系统的设计。结论是: 没有某种算法能够完全解决问题, 多重算法+交互设计, 才能解决特定场景的需求。下文也对之前的一些博文进行梳理,构成一个完整工业界推荐系统所具有的方方面面(主要以百度关键词搜索推荐系统为例)
完整的推荐系统肯定不会只用一种推荐算法 在学术界, 一般说到推荐引擎, 我们都是围绕着某一种单独的算法的效果优化进行的, 例如按内容推荐, 协同过滤(包括item-based, user-based, SVD分解等),上下文推荐,Constraint-based推荐,图关系挖掘等。 很多比较牛的单个算法, 就能在某个指标上取得较好效果, 例如MAE,RMSE......不过有自己的优点, 每种算法也有自己的缺点, 例如按内容推荐主要推荐和用户历史结果相似的item,一般的item-based容易推荐热门item(被更多人投票过)......所以在工业界,例如各互联网公司, 都会使用多种算法进行互相配合, 取长补短, 配合产品提升效果。而且在完整的推荐系统中,不仅有传统的Rating推荐, 还需要辅以非常多的挖掘, Ranking来达到预期效果。
推荐系统3大件:User Profile、基础挖掘推荐、Ranking
在实践中, 一个完整的推荐系统会主要由3部分组成: - User Profile
- 基础推荐挖掘算法
- Ranking
此处之所以将Ranking单独列出来,是因为其在推荐任务中过于重要,直接决定了推荐的效果。
以下为整个推荐的数据流:
User Profile A user profile is a representation of information about an individual user that is essential for the (intelligent) application we are considering user profile主要是用户(注册)信息,以及对用户反馈的信息进行处理,聚合,用于描述用户的特征; 是后续推荐和排序的基石。 一般情况下,user profile会包含以下具体内容:
用户兴趣数据 用户的基础注册信息,背景信息:例如用户出生地,年龄,性别,星座,职业等。这些信息一般从用户注册信息中获取;例如高德,百度地图注册用户,淘宝注册用户等用户行为反馈:包括显示的反馈(explicit)和隐藏(implicit)的反馈,显示的反馈包括用户的评分,点赞等操作,百度关键词搜索推荐工具上的点赞(正向显示反馈)和垃圾桶(负向显示反馈),淘宝上的评分;隐式反馈包括用户的浏览行为,例如在百度关键词搜索推荐上搜过那些词,淘宝上点击了那些页面,在高德上点击了那些POI等用户交互偏好:例如用户喜欢使用哪些入口,喜欢哪些操作,以及从这些操作中分析出来的偏好,比如在高德地图上根据用户行为反馈分析出来的用户对美食的偏好:更喜欢火锅,粤菜,还是快餐用户上下文信息:这些信息有些是分析出来的,例如在LBS中分析出来的用户的家在哪儿,公司在哪儿,经常活动的商圈,经常使用的路线等user profile经常是一份维护好的数据,在使用的时候,会直接使用该数据,或是将该数据存储在KV系统中,供Online系统实时使用。 在搜索或是推荐的场景下,每次请求一般只会涉及到一次user profile的KV请求,所以online使用的时候,主要的实现困难是存储,以及快速KV的快速响应。
基础挖掘推荐算法 基础挖掘推荐算法, 主要使用传统推荐算法, 结合分析的item profile和user profile, 建立user和item的关系,此时并不会过多考虑其他因素,例如是否冷门/热门,最主要的就是建立user和item的关系。?在各种论文中狭义的推荐,主要就是指该部分内容。 主要围绕着Rating,以及Top N进行该处的Top N(更像是直接Rating值最高的Top N) 传统的推荐算法研究主要围着这块工作进行,现在已经有很多比较成熟的算法,这些算法相关的研究可参见博文:《推荐系统经典论文文献及资料》;其中也能找到业界较多成功推荐系统的实践分享 主要包含以下几类: Content Based推荐: 按内容推荐,主要的工作是user profile, item profile的提取和维护,然后研究各种相似度度量方法(具体相似度度量参见博文:《推荐系统中的相似度度量》)
Constrainted-based推荐:根据限制性条件进行演绎推荐 在实际应用时,我们经常使用按内容推荐,item-based寻找从感知的角度比较靠谱的结果,使用SVD,SVD++,图关系寻找更深层次的联系结果。同时在推荐时,会结合很多因素来进行综合排序,例如关键词, 或是LBS中POI的热度等。具体可参见下文ranking部分。
算法效果衡量 以上这些算法, 我们在离线的时候,使用Cross-Validation方式,就可以分析出其效果,而且离线分析的时候,代价比较小,比较容易操作。当然,对于不同的问题会使用对应的指标进行衡量。 对于预测Rating准确性主要是用RMSE,或是MAE;具体可参见博文:《关键词搜索推荐系统中的推荐准确性度量》 如果是排序, 则更多使用NDCG,MAP, ?MRR等指标;具体可参见博文:《使用ndcg评估关键词推荐系统的相关性》 在具体应用场景中,对于特定推荐问题,会涉及到选用哪种算法的问题。推荐不像CTR预估这样的问题,目标比较单一,经常我们需要考虑多个指标,而且这些指标可能此消彼长,需要做权衡,例如需要考虑算法的准确性(accuracy),同时也需要考虑算法的覆盖(coverage),置信度(confidence),新鲜度(novelty)和惊喜度(Serendipity),同时还需要考虑推荐为系统带来的收益和效用(utility)。 这些指标经常需要权衡,而且经常提升某一个的时候会导致其它下降,所以有时候存在一定的主观性:我们到底看中哪一个指标? ?而且这个问题可能随着系统,平台所处的阶段而不同。 例如在建立口碑的时候,我们可能不太关注coverage,而更关注accuracy,因为要让用户建立一种:该系统很准的认知;如果在系统已经比较成熟了,此时可能需要考虑novelty, serendipity的同时,还需要考虑utility:该推荐能为系统带来什么收益,例如对百度的变现有多大收益? 对淘宝的销售有多少收益等 具体这些指标的选择可参见博文:《选择推荐算法时需要考虑得因素》
Ranking,此部分是成熟的搜索,推荐系统具有的核心逻辑 比较简单的实现方法, 是直接对各种特征拍阈值进行线性加权,比较成熟的系统一般会使用机器学习的方式和综合个维特征, 学习出模型后进行排序, 例如使用Learning to rank技术。 该部分需要考虑的因素较多较为复杂。 和传统的推荐相比, 此处单独将Ranking拿出来。 基础推荐挖掘, 和传统的推荐部分比较类似,主要结合user profile, 挖掘哪些item适合推给哪些user。 但仅根据这些挖掘就直接进行推荐是不够的。 真实online推荐场景中, 需要考虑更多其他因素, 例如:相关性,推荐的上下文,CTR预估,以及商业业务规则。 相关性: item与用户的相关性,这是大多数搜索和推荐任务的基石,例如在搜索中判定一个query和一个document的相关性,或是一个query 和 另一个query的相关性,或是在特征比较多的情况下, 一个user 和一个item 记录的相关性;实现方式可以很简单,例如传统的相似度度量方式(参见博文:《推荐系统中的相似度度量》),对于文本,业界使用简单的TF*IDF,或是BM25; 不过很多时候我们需要增加更多维度特征,包括推荐item本身的重要性,例如IDF,Pagerank(具体参见博文:《pagerank的经济学效用解释》),同时使用模型来提升相关性判断的准确性。使用模型的方式会更加复杂,但效果提升也非常明显。具体可参见博文:《集成树类模型及其在搜索推荐系统中的应用》,《分类模型在关键词推荐系统中的应用》,《adaboost》
推荐的上下文:例如推荐产品的入口,交互方式, 不同的入口,甚至同一入口的不同交互方式, 推荐的结果有可能都需要不一样; 在LBS生活服务中, 请求发生的时间, 地点也是推荐需要重点考虑的上下文因素,例如饭点对餐饮item的提权; 异地情况下对酒店等结果的加权等
CTR预估:成熟的商业系统都会使用模型来完成CTR预估,或是转化预估 以及商业业务规则:例如黑白名单,或者强制调权。例如在百度关键词搜索推荐中,某些有比较高变现潜力的词, 就应该加权往前排; 比如在高德LBS服务中,有些海底捞的店点评评分较低, 但我们也应该往前排;或是在搜索引擎中,搜国家领导人的名字, 有些最相关的结果可能因为法律因素是需要屏蔽的
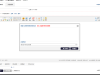
算法评估 很直接,离线调研的时候看就看算法的评估指标,参见博文:《关键词搜索推荐系统中的推荐准确性度量》,《使用ndcg评估关键词推荐系统的相关性》 上线的时候,进行圈用户(圈定某两个user集合作为实验/对照用户组)实验, 或者圈请求实验(例如随机圈定5%流量进行实验),之后根据系统效果监控中的指标值判断实验效果。以下为一个典型的效果监控截图: 实验如果证明成功,达到预期效果,一般之后推广到全流量;反之,如果实验未达到预期效果,则需要分析什么地方有问题,如何改进,之后继续调整算法继续实验。当实验较多时,还会涉及较多工程问题,例如分层实验框架等。
系统效果监控 对于整个系统,需要建立晚上的效果监控平台进行效果的实时监控,以便发现用户的行为模型,系统的不足,分析后续的发力点等。一般这样的监控平台会使用Dashboard来完成,基本的框架是前段UI + 后端数据库。很多时候,离线统计策略在hadoop上处理统计日志计算指标,并将计算出来的指标存入数据库,前端UI访问数据库,拉出指定时间段内某些指标的值,并进行简单分析。 具体的监控指标,及指标体系的建立,可参见博文:《搜索引擎变现策略指标体系》
交互设计 完整的产品包括便捷的交互和背后牛叉的算法。很多时候,要提升推荐的效果,需要算法和交互配合,才能达到理想的效果: 交互需要有健壮的算法产出结果;而算法也需要有配套的交互,才能达到预期效果,否则再牛叉的算法,对结果的影响也可能没那么明显。 一些交互的例子参见博文:
说了那么多,中心就是想说明, 一个完整的推荐系统,远远不止是一两个rating算法能够覆盖的,而且此处还未涉及工程部分。
|