针对Liunx,Windows自行扩展。
* 无需Python3支持
脚本代码如下:
#!/bin/bash
########################################################
# 程序名称: 海洋CMS自动采集脚本
# 版本信息:seacmsbot/1.2
# 发布链接: https://www.seacms.net/thread-8253.htm
# 使用方法:直接复制代码到宝塔计划任务shell脚本内容里添加每小时任务使用
# 更新时间:2019.9.26
##########################################################
#请修改下面的网站域名及管理目录
web_site="http://网站域名/管理目录/admin_reslib2.php"
#请修改下面项内容为"admin_reslib2.php"里设置的访问密码(默认为系统设置的cookie密码)
web_pwd="8888e82e85bd4540f0defa3fb7a8e888"
#下面项内容为资源站每日采集链接地址列表,请自行修改,每行一条,可添加多个,前后需添加引号。
#每日采集链接获取方法:选择"后台-采集-资源库列表",复制资源站右边的"采集每天"的链接地址,去掉?前面的内容。
web_api=(
'?ac=day&rid=1&url=https://api.iokzy.com/inc/ldg_seackm3u8s.php'
'?ac=day&rid=2&url=http://www.zdziyuan.com/inc/s_ldgm3u8_sea.php'
)
#模拟用户浏览器ua,请勿随意修改,以免被目标防火墙拦截!
web_ua="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/76.0.3809.100 Safari/537.36 seacmsbot/1.2;"
#采集单页
function get_content() {
echo "正在采集第$page页..."
#echo " get_content: --->url:--->$1"
cResult=$(curl --connect-timeout 10 -m 20 -k -s -L -A "$web_ua" "$1" )
echo $cResult | grep -q "采集"
#echo -e "$1\n$cResult"
if [ "$?" = "0" ]; then
next_content "$cResult"
else
echo -e "采集失败,请检查设置!\n失败链接-->$1\n返回信息-->$cResult\n采集结束,共0页"
fi
}
#采集下页
function next_content() {
#统计数据
Result=$(echo "$1" | tr "
" "\n")
a=$(echo "$Result" | grep -c "采集成功")
b=$(echo "$Result" | grep -c "更新数据")
c=$(echo "$Result" | grep -c "无需更新")
d=$(echo "$Result" | grep -c "跳过")
echo "采集成功-->已更$c部,新增$a部,更新$b部,跳过$d部"
let add+=$a
let update+=$b
let none+=$c
let jmp+=$d
#检测并采集下页
next_url=${1##*location.href=\'}
next_url=${next_url%%\'*}
#echo $next_url
if [ "${next_url:0:1}" = "?" ]
then
let page++
get_content "$web_site$next_url"
else
echo "采集结束,共$page页"
fi
}
#脚本入口
echo "海洋CMS自动采集脚本开始执行 版本:v1.2"
starttime=$(date +%s)
update=0 #更新
add=0 #新增
none=0 #无变化
jmp=0 # 跳过
for url in ${web_api[@]};
do
if [[ ! -z $url ]]
then
web_param="$web_site$url&password=$web_pwd"
page=1
echo "开始采集:$url"
get_content $web_param
fi
done
endtime=$(date +%s)
echo "============================"
echo "入库-->$add部"
echo "更新-->$update部"
echo "跳过-->$jmp部(未绑定分类或链接错误)"
echo "今日-->$[none+add+update]部"
echo "============================"
echo "全部采集结束,耗时$[endtime - starttime]秒"根据个人环境修改,不做赘述。
实际采集网址获取办法:
第一步: 登录网站后台,进入资源库列表,在你要采集的目标上点击右键 ,比如在"采集当天"上点击鼠标右键,选择"复制链接地址"
比如这里是:
http://127.0.0.1/admin/admin_reslib.php?ac=day&rid=1&url=https://api.iokzy.com/inc/ldg_seackm3u8s.php第二步:去掉上一步复制到的内容"?"前面的内容,结果如下:
?ac=day&rid=1&url=https://api.iokzy.com/inc/ldg_seackm3u8s.php这样就得到了最终的采集网址
* 设置定时任务
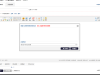
1. 如果是宝塔,添加到计划任务shell脚本内容,设置为每小时执行,保存即可。
4k11fthiay1.jpg

2. 非宝塔,可以用系统的计划任务,方法是:
把修改好的代码,另存为"/var/www/job/seacmsbot.sh" ,在终端执行下面的代码即可:
chmod +x var/www/job/seacmsbot.sh
echo "* */1 * * * var/www/job/seacmsbot.sh">>/etc/crontab
service crond start |